Storm确保每条从Spout发出的消息都会被充分处理。本文介绍其实现机制以及用户如何使用Storm的可信性特性。
消息被“充分处理”的含义是什么?
从Spout发出的一个元组可能触发成千上百个新元组。例如,考察下面这个单词计数拓扑:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));
这个拓扑从Kestrel队列读出一系列句子并将其分割为单词,然后将截止这一时刻所接收到的每个单词的个数发射出去。从Spout发出的元组触发了许多新的元组:句子中的每个单词生成一个元组,并且每次更新单词数目时也生成一个元组。消息树的结构如下所示:
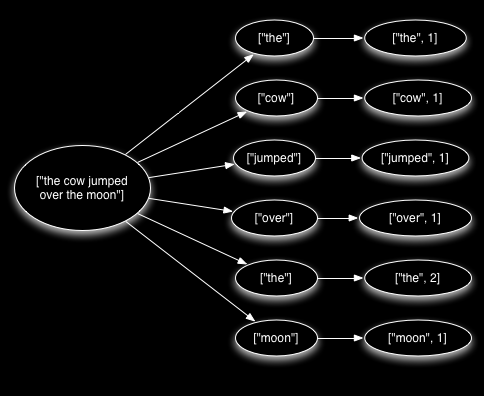
当元组树被遍历且树中的每条消息都被处理了之后,Storm即认为从Spout发出的元组被“充分处理”。如果在指定的超时时间内消息树没有被充分处理,则元组被认为处理失败。超时时间可以使用Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS在拓扑级别指定,其默认值为30秒。
消息被充分处理或处理失败之后会发生什么?
要理解这个问题,我们首先来看一下从Spout发出的元组的生命周期。作为参考,下面给出Spout实现的接口(参考Javadoc):
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
首先,Storm通过调用Spout的nextTuple方法从Spout获取元组。Spout使用open方法提供的SpoutOutputCollector对象来向它的一个输出流发射元组。发射元组时,Spout提供一个”消息id”用来标识元组。例如,KestrelSpout从Kestrel队列读取消息并将Kestrel提供的id作为”消息id”发射出去。向SpoutOutputCollector发射消息的代码如下:
_collector.emit(new Values("field1", "field2", 3) , msgId);
接下来,元组被发送到消费Bolt,而Storm则负责跟踪创建的消息树。如果Storm检测到一个元组被充分处理,它会使用Spout提供的消息id去调用最初的Spout任务的ack方法。同理,如果元组超时则Storm会调用Spout的fail方法。注意,元组将由创建它的Spout任务来确认成功或失败。所以,如果Spout作为集群中的多个任务来运行,元组不会由其他的任务确认成功或失败。
下面仍然以KestrelSpout为例来说明Spout如何确保消息被处理。当KestrelSpout从Kestrel队列读出一条消息时,相当于它”打开”了这条消息。这时消息并没有真正从队列中移除,而是处于一个”等待”状态来等待系统确认消息被成功处理。在等待状态中,消息不会被发送给队列的其他消费者。而且,如果一个客户端断开了连接,则相关的所有处于等待状态的消息都将被放回队列。客户端打开消息时,Kestrel会随同消息数据一起提供一个唯一的消息id。KestrelSpout将此id作为向SpoutOutputCollector发射元组时使用的”消息id”。稍后,调用KestrelSpout的ack或fail方法时,KestrelSpout会向Kestrel发送带有消息id的确认成功或失败的消息来将消息从队列中移除或放回队列。
Storm的可信性API什么?
要利用Storm的可信性特性,用户需要完成两件事情。首先,在消息树中创建新边时需要通知Storm。其次,处理完每一个元组时需要通知Storm。只要用户完成了这两个操作,Storm就可以检测到元组树何时被处理完毕,从而可以相应地确认Spout发射出的元组的处理结果。Storm为这两个任务提供了简洁的方案。
指定元组树中的一条边被称为_定锚_。定锚在用户发射新的元组时完成。下面的Bolt是一个例子。它将一个包含一条句子的元组分割成只包含一个单词的多个元组:
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
通过将输入元组作为emit的第一个参数,每个单词元组被_锚定_。由于单词元组被锚定,如果此元组在下游未能被成功处理,则树根部的Spout元组将被重新发射。作为对比,下面来看看如果单词元组被这样发射会发生什么:
_collector.emit(new Values(word));
这样发射的单词元组将是_未锚定_的。如果此元组在下游未能被成功处理,树根部的Spout元组不会被重新发射。根据用户拓扑对容错性程度的要求,有时发射未锚定的元组更加合理。
输出元组可以被锚定到多个输入元组。在进行流的连接或聚合时这一点很有用。多锚定的元组在处理失败时将导致Spout发出的多个元组被重新发射。多定锚是通过指定一个元组链表来实现的。如下例所示:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
多定锚将输出元组加入到多棵元组树中。注意,多定锚可能打破树结构的限制从而生成一个元组DAG,如下图所示:
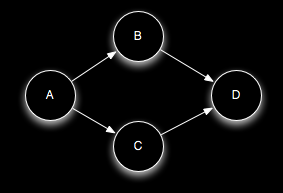
Storm的实现对DAG和树同样有效(之前的版本只对树有效,而且“元组树”这个名称并不准确)。
定锚是用户描述元组树的方法,也是Storm可信性API中用来描述用户何时处理完元组树中的一个元组的最后一部分内容。这是通过调用OutputCollector的ack和fail方法完成的。如之前的SplitSentence所示,输入元组在所有单词元组被发射之后才被确认成功。
用户可以调用OutputCollector的fail方法来立即使元组树根部的Spout元组失败。例如,应用程序可能需要处理数据库连接异常并显式使输入元组失败。显式确认失败可以使得Spout元组更快地被重新发送(无需等待超时)。
所有被处理的元组都必须被确认成功或失败。Storm使用内存来跟踪每个元组,所以如果用户不对每个元组进行确认,任务最终将耗尽内存。
很多Bolt遵从读入输入元组、发射新元组、在execute方法末尾确认元组的常见模式。这些Bolt可以化为过滤器和简单功能的类别。Storm提供了一个叫做Basicbolt的接口来封装这种模式。SplitSentence示例可使用BasicBolt重写:
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
这份实现比之前的更加简单而且语义上是等价的。发射给BasicOutputCollector的元组被自动锚定到输入元组,execute方法结束时输入元组被自动确认成功。
作为对比,进行聚合或连接的Bolt可能会等到一批元组被计算出结果之后才会确认输入元组。聚合和连接一般会将输出元组进行多锚定。这些操作就不是IBasicBolt的模式所能涵盖的了。
如果元组可被重新发送,如何保证应用程序正确运行?
如软件设计中的通常情况一样,答案是“看情况”。Storm 0.7.0引入了”事务拓扑”的特性,它为用户提供了完全容错、保证消息被处理一次的语义,这可以应对大多数计算情形。关于事务拓扑请参考这里。
Storm如何高效实现可信性?
Storm集群使用一个特殊的”acker”任务集用来跟踪每个Spout元组的元组DAG。acker观察到DAG结束之后,会向创建Spout元组的Spout任务发送一条确认消息。用户可以通过Config.TOPOLOGY_ACKER_EXECUTORS设置拓扑的acker执行线程的数目。TOPOLOGY_ACKER_EXECUTORS默认和拓扑的工作进程的数目相同,如果拓扑需要处理大量的消息,可能需要适当增大这个值。
要理解Storm的可信性特性实现原理的最好方法是考察元组的生命周期和元组DAG。当元组在拓扑中被创建时,不管是被Spout还是Bolt创建的,它都会被指定一个64位的id。这些id被acker用来跟踪每个Spout元组的元组DAG。
每个元组都知道它所在元组树的Spout元组的id。在Bolt中发射新元组时,新元组所锚定的Spout元组的id被一并拷入。确认元组时,它向相应的acker任务发送一条描述元组树变化情况的消息。更准确地说,内容是“我在这个Spout元组的树中已经处理完毕,这里是锚定到我的所有新元组”。
例如,如果元组”D”和”E”基于元组”C”创建,下面是”C”被确认之后元组树的变化情况:
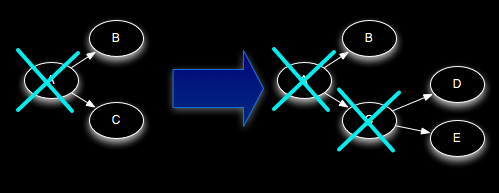
由于”C”是在”D”和”E”被加入树的同时被从树中移除的,所以树永远不会提前完成。
关于Storm如何跟踪元组树还有一些细节需要说明。如之前提到的,在拓扑中可以指定任意数目的acker任务。这就导致了一个问题:当元组在拓扑中被确认时,它如何知道向哪个acker任务发送消息呢?
Storm使用模哈希将Spout元组id映射到acker任务。由于每个元组都携带着所在元组树的Spout元组的id,所以它们可以知道和哪个acker任务通信。
另一个细节是acker任务是如何知道哪个Spout任务对其所跟踪的Spout元组负责。当Spout任务发射新元组时,它向相应的acker发送一条消息说明它的任务id对所发射的Spout元组负责。这样,当acker看到一棵树被完成时,它就可以知道该向哪个任务发送结束消息了。
Acker任务并不显式跟踪元组树。对于包含成千上万个甚至更多个节点的元组树来说,跟踪所有的树将需要大量内存。事实上,acker采用了一种不同的策略,只需要为每个Spout元组分配固定大小的空间(约20字节)。这种跟踪算法是Storm之所以成功的一个关键之处,也是它的一个重大突破。
acker任务存储一个map,键为Spout元组id,值是一个二元组。二元组的第一个值是创建Spout元组的任务id,后面用来发送完成消息。二元组的第二个值是一个叫做“ack值”的64位整数。ack值可以表示任意大小的整棵元组树的状态,它实际上是树中所有被创建/确认的元组的id的异或值。
当acker任务观察到一个ack值变为0时,它可以认为对应的元组树已经完成。由于元组id是随机的64位证书,所以ack值意外变为0的概率非常小。简单计算可知,如果每秒确认10,000次,需要50,000,000年才会发生一次错误。即使发生了错误,也只会使得碰巧失败的元组对应的数据被丢失。
上面介绍了可信性算法,现在来看一下有哪些可能的失败情形以及Storm如何避免数据丢失:
- 任务异常终止,元组未被确认:这种情况下,失败元组所在树根部的Spout元组会由于超时而被重新发送。
- Acker异常终止:这种情况下,acker所跟踪的所有Spout元组都会由于超时而被重新发送。
- Spout任务异常终止:这种情况下,Spout所连接的源负责重新发送消息。例如,Kestrel或者RabbitMQ队列会在客户端断开连接时将所有处于等待状态的消息放回队列。
可见,Storm的可信性机制是完全分布式、可伸缩和容错的。
调节可信性
Acker任务是轻量级的,所以拓扑中并不需要很多。可以通过Storm UI来跟踪它们的性能(节点名称为”__acker”)。如果吞吐量不理想,就需要添加更多的acker任务。
如果可信性对用户并不重要——即用户并不在意在失败情形下丢失元组——那么用户可以通过停止跟踪Spout元组的元组树来提高性能。这可以降低一半的消息发送量,因为一般情况下元组树中的每个元组都有对应的确认消息。另外,在下游的元组中需要存储的id数目也减少了,这进一步降低了所需带宽。
有3种方法可以移除可信性。第一种是将Config.TOPOLOGY_ACKERS设置为0。这种情况下,Storm会在spout发射元组之后立即调用ack方法。元组树将不会被跟踪。
第二种方法是在消息级别移除可信性。可以通过在SpoutOutputCollector.emit方法中省略消息id来停止跟踪特定Spout元组。
最后,如果用户只是不关心拓扑中特定的下游元组集合是否被成功处理,可以将它们发射为未锚定的元组。由于它们没有被锚定到任何Spout元组,即使它们没有被确认也不会引起Spout元组被重新发送。